Go语言的内存镇流器
- Published on
“内存镇流器”(Memory Ballast)是一个形象的比喻,指的是一种优化Go程序内存使用的技术。就像船舶使用压舱物来增加稳定性一样,Go程序也可以通过预先分配一定量的内存来提升性能和稳定性,尤其是在应对突发流量时。
背景介绍
在Twitch平台上,有一个名为Visage的服务,它作为API前端,是所有外部出站API流量的中央网关。Visage负责处理多项关键任务,包括授权、请求路由以及服务端的GraphQL处理。因此,它需要具备良好的扩展能力,以应对用户流量的波动,这些流量模式有时可能超出我们的控制。作为API网关,Visage在Twitch的后端服务与外部世界之间扮演着关键角色,它的性能直接影响到用户体验和平台的整体稳定性。
例如,大型互联网公司常常遇到一种被称为 “刷新风暴” 的流量模式。这种情况通常发生在一个受欢迎的主播因网络问题掉线时。主播重新开始直播后,观众会纷纷刷新他们的页面,导致服务器突然面临大量的API请求流量。
挑战与应对
Visage是一个基于Go语言开发的应用(在此次优化中使用的是Go 1.11版本),运行在Amazon EC2实例上,并配有负载均衡器。尽管EC2结合自动扩展组的能力能够很好地进行水平扩展,但在应对突发的巨大流量时,依然存在挑战。
在“刷新风暴”期间,服务器需要在几秒钟内处理数百万个请求,流量激增可能是平时的20倍。工程师们发现,当前端服务器负载过高时,API的响应延迟会显著增加,从而影响用户体验。
一种简单的解决方案是始终保持高冗余的服务器容量,以应对这些突发情况,但这种做法非常浪费且成本高昂。为了减少这些持续上升的成本,工程师们决定探索能够提高单台服务器吞吐量,并在负载高峰时提供更稳定请求处理的优化方案。经过研究,他们找到了“内存镇流器”这一技术,以帮助改善内存管理和程序的整体性能。
方案调研
在优化过程中,工程师们在生产环境中运行了 pprof,这使得获取真实生产流量下的性能分析变得非常容易。如果你还没有使用过 pprof,我强烈建议你开始使用它。大多数情况下,性能分析器对CPU的负载影响非常小。即使是执行跟踪器,尽管有一些开销,但影响微乎其微,可以在生产环境中每小时运行几秒钟,而不会对服务造成显著影响。
通过对Go应用的性能分析,我们得出以下观察结果:
- 在稳定状态下,我们的应用每秒大约运行8-10次垃圾回收(GC)周期(每分钟400-600次)。
- 超过30%的CPU时间消耗在与GC相关的函数上,这一比例相当高,表明存在很大的优化空间。
- 在流量激增期间,GC周期数量进一步增加,这会加剧性能问题,导致应用响应时间变长。
- 我们的堆内存大小相对较小,这表明内存使用效率较高,但也可能导致频繁的GC触发。
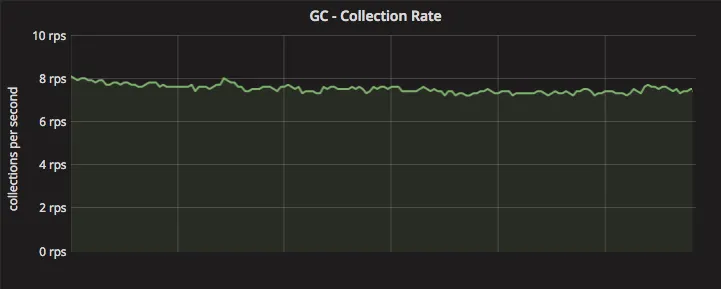
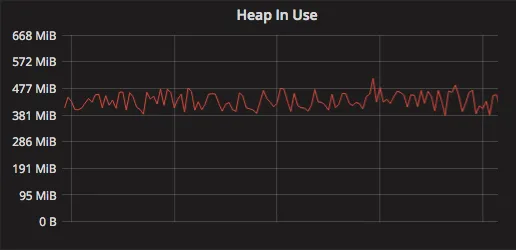
我们此次改进的重点是优化应用程序的垃圾回收性能,以提升整体处理能力。
什么是垃圾收集器(GC)?
在现代编程中,通常有两种方式来分配内存:栈(stack)和堆(heap)。大多数程序员在第一次写出导致栈溢出的递归程序时,就已经对栈有了初步的了解。而堆则是一个用于动态内存分配的区域,适用于那些生命周期无法在编译时确定的对象。
栈内存的分配优势在于其生命周期与所属函数绑定,因此,当函数返回时,栈上的内存会自动释放。而堆上的内存则不会在超出作用域时自动释放。为了防止堆内存无限增长,我们要么手动释放内存,要么依赖像Go这样的编程语言中的垃圾收集器(GC),来查找并清除不再被引用的对象。
通常情况下,在有GC机制的语言中,尽可能多地在栈上分配内存是有益的,因为这些内存分配不会被GC察觉。Go语言通过逃逸分析(escape analysis)来确定对象是应该分配在栈上还是堆上。
然而,在实际应用中,编写只在栈上分配内存的程序往往非常受限。因此,我们依赖Go的高效垃圾收集器来维护堆内存的清洁,确保程序的性能和稳定性。
Go的垃圾收集器
垃圾收集器是复杂的软件组件。
从Go 1.5版本开始,Go引入了一个标记-清除(mark-and-sweep)垃圾收集器。顾名思义,这种GC机制包括两个主要阶段:标记和清除。与传统的“全程暂停应用程序”(Stop The World, STW)的垃圾回收不同,Go的GC在大多数情况下能够与应用程序代码并发运行,从而减少对程序执行的影响。
标记和清除阶段
标记阶段:运行时会遍历堆中所有被应用程序引用的对象,并将这些对象标记为“仍在使用中”。这些对象被称为活动内存。标记阶段的任务是找出所有仍然有用的数据,以确保它们不会被错误地回收。
清除阶段:在标记阶段完成后,所有未被标记的对象就会被认为是垃圾。清除阶段的任务是将这些未被引用的对象从堆中移除,释放出相应的内存。
在整个GC周期中,虽然清除操作本质上是“STW”的,但由于现代操作系统在释放内存时的速度非常快,清除阶段所占用的时间通常较短。因此,标记阶段是影响GC时间的主要因素。
关键术语
- 堆大小:包括堆中所有的内存分配,既包含当前被使用的,也包含已经成为垃圾的部分。
- 活动内存:指正在被应用程序引用的内存分配,是当前有用的部分,不包括垃圾。
标记阶段与性能的关系
在标记阶段,运行时需要遍历应用程序当前引用的所有对象,因此标记所需的时间与活动内存的大小成正比,而与总堆大小无关。这意味着,即使堆中有大量的垃圾对象,也不会显著增加标记阶段所需的时间。因此,理论上讲,拥有更多垃圾对象并不会明显延长GC周期。
然而,这种设计存在权衡。减少GC触发的频率,意味着垃圾清理的时间间隔变长,从而在内存中会积累更多的垃圾对象。这种权衡的结果就是:随着GC间隔的增加,系统内存消耗会变高。
Visage应用程序中的实际问题
在Visage应用程序中,我们注意到它运行在专有的虚拟机上,拥有64GiB的物理内存,但即便如此,应用程序的GC非常频繁,而实际使用的物理内存仅约400MiB。这种现象表明GC频率过高,造成了CPU资源的浪费。要理解这种情况,我们需要深入了解Go如何在GC频率和内存使用之间进行权衡,这就涉及到Go垃圾收集的步调控制器(Pacer)。
Pacer(步调控制器)
Go 的 GC 使用 步调控制器 来决定何时启动下一个 GC 周期。这被建模为一个控制问题,它试图找到正确的时机来触发 GC 周期,以达到目标堆大小。默认情况下,Go 的步调控制器会尝试在堆大小每次翻倍时启动一个 GC 周期。这是通过在当前 GC 周期的标记终止阶段设置下一个堆触发大小来实现的。因此,在标记完所有活动内存后,它可以决定在总堆大小是当前集合的 2 倍时运行下一次 GC。这个 2 倍值来自运行时使用的 GOGC 环境变量设置的触发器比率。
在我们的场景中,步调控制器有效地将堆上的垃圾保持在最小限度,但代价是引入了大量不必要的GC操作,因为应用程序仅使用了系统内存的约0.6%。
引入内存镇流器(Ballast)
我们通过在应用程序启动时分配一个大型字节数组(例如10 GiB)来实现内存镇流器,这样做的目的是增加堆的稳定性:
func main() {
// 创建一个10 GiB的大型堆分配
ballast := make([]byte, 10<<30)
// 继续执行应用程序
// ...
}
解释
1. 为什么使用内存镇流器?
如前所述,GC 会在堆大小每次翻倍时触发。堆大小是堆上所有分配的总大小。因此,如果分配了 10GB 的镇流器,下一次 GC 只会在堆大小增长到 20GB 时触发。此时,大约会有 10GB 的镇流器 + 10GB 的其他分配。
当 GC 运行时,镇流器不会被当作垃圾清除,因为我们在 main 函数中仍然保持对它的引用,因此它被视为活动内存的一部分。由于我们应用程序中的大多数分配只在短暂的 API 请求生命周期内存在,10GB 分配中的大部分将被清除,将堆大小再次减小到略高于 ~10GB (即 10GB 镇流器加上所有正在进行的请求中被认为是活动内存的分配)。现在,下一个 GC 周期将在堆大小(当前略高于 10GB)再次翻倍时发生。
因此,镇流器增加了基本堆大小,使得我们的 GC 触发被延迟,随时间推移 GC 周期的数量减少。这个改变如预期那样起作用了 - 我们看到 GC 周期减少了约 99%:
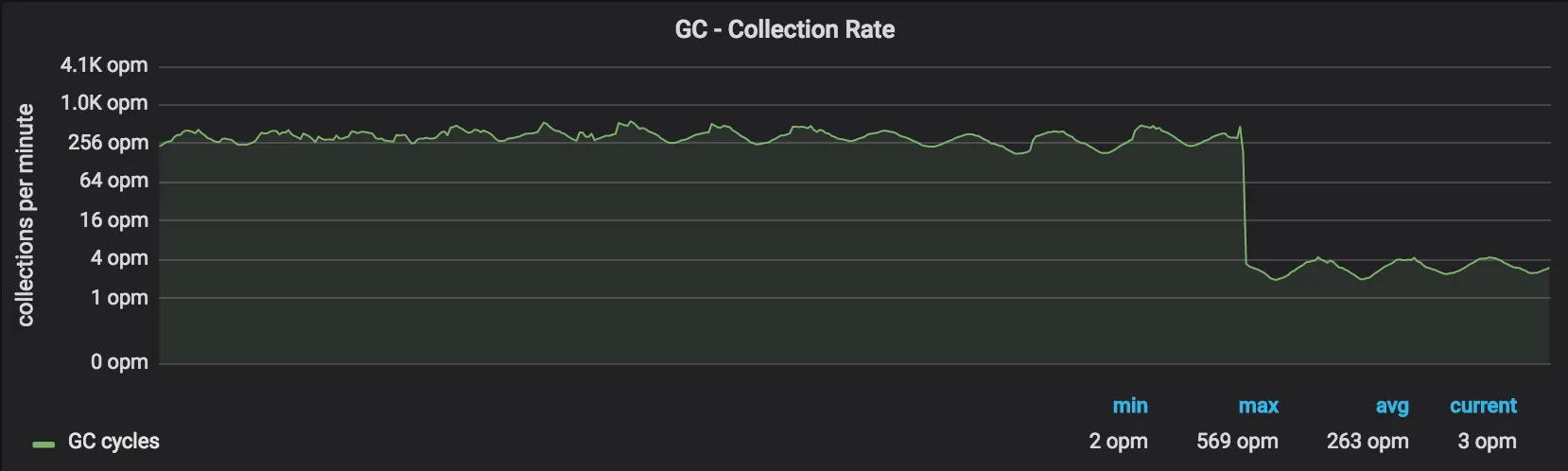
那么这看起来不错,CPU使用率呢?
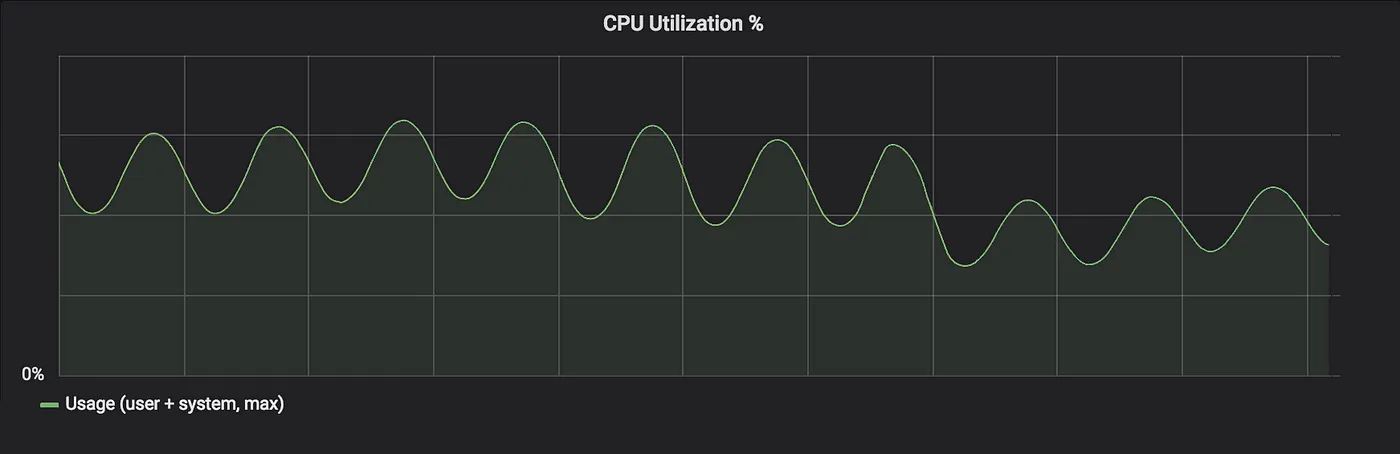
绿色的正弦波形CPU指标是由我们流量的每日波动引起的。可以看到改变后有一个明显的下降。
~30%的CPU减少意味着不用进一步观察,我们可以将波动减少30%,然而我们也关心API延迟——稍后会详细讨论这一点。
如前所述,Go运行时提供了一个GOGC环境变量,允许对GC步调控制器进行非常粗略的调整。这个值控制堆在运行GC之前的增长比例。我们决定不使用它,因为它有一些明显的缺点:
- 比例本身对我们来说并不重要;我们使用的内存量才是。
- 我们必须将值设置得非常高才能获得与镇流器相同的效果,使得该值对活动堆大小的小变化很敏感。
- 推理活动内存及其变化率并不容易;而思考总使用内存则很简单。
如果你想知道为什么我们使用字节数组作为镇流器,这保证我们只向标记阶段添加一个额外的对象。因为字节数组没有任何指针(除了对象本身),GC可以在O(1)时间内标记整个对象。
2. 这不会浪费10 GiB的物理内存吗?
简短的回答是:不会,除非你在代码中访问这些内存。在Unix系统(包括Windows)中,内存是通过操作系统的页表进行映射的。尽管make([]byte, 10<<30)会在程序的虚拟地址空间中创建一个10 GiB的数组,但实际的物理内存只有在对该数组进行读写时才会被分配。只有当我们试图读取或写入切片时,才会发生页面错误,导致支持虚拟地址的物理 RAM 被分配。
可以通过以下简单程序进行验证:
func main() {
_ = make([]byte, 100<<20)
<-time.After(time.Duration(math.MaxInt64))
}
运行程序后使用ps查看内存分配:
%MEM COMMAND PID MAJFL MINFL RSS VSZ
0.2 test_alloc 27826 0 1003 4.8M 108M
这表示进程的虚拟内存分配(VSZ)约为100 MiB,但实际占用的物理内存(RSS)仅为~5 MiB。
接下来,如果我们修改程序,让它写入一半的字节数组:
func main() {
ballast := make([]byte, 100<<20)
for i := 0; i < len(ballast)/2; i++ {
ballast[i] = byte('A')
}
<-time.After(time.Duration(math.MaxInt64))
}
再次检查ps输出:
%MEM COMMAND PID MAJFL MINFL RSS VSZ
2.7 test_alloc 28331 0 1.5K 57M 108M
正如预期的那样,现在字节数组的一半在 RSS 中,占用物理内存。VSZ 没有变化,因为在两个程序中都存在相同大小的虚拟分配。
对于那些感兴趣的人,MINFL 列是次要页面错误的数量 - 这是发生在进程中需要从内存加载页面的页面错误数量。如果 OS 成功地很好地连续分配了我们的物理内存,那么每个页面错误将能够映射多个 RAM 页面,减少发生的总页面错误数量。
总结:
- 内存镇流器的优势:通过增加堆基准大小,内存镇流器减少了GC周期的频率,从而降低了CPU的使用率,提升了应用程序的整体性能。
- 物理内存的利用:镇流器作为虚拟分配存在,只要不读写它,其内存开销几乎不会反映在实际的物理内存中。
API延迟
正如前面提到的,我们观察到减少GC频率后,API延迟得到了改善,尤其是在高负载期间。最初,我们猜测这是因为GC暂停时间减少了。然而,改变前后GC暂停时间的差异并不显著,而且暂停时间仅为单位数毫秒,而我们在峰值负载时观察到的延迟却达到100毫秒级。
要更好地理解延迟改善的原因,我们需要探讨Go GC中的一个重要特性——GC assists。
GC assists
GC assists机制会在GC周期期间将部分内存分配工作转移到正在执行分配操作的goroutine上。没有这种机制,Go运行时就无法在GC周期期间控制堆的增长。
Go已经有一个后台GC工作线程,而__“assists”__意味着用户的goroutine会帮助后台GC线程进行特定的工作,尤其是标记阶段的工作。
为了更好地理解这一点,让我们看一个例子:
someObject := make([]int, 5)
当这段代码执行时,goroutine通过一系列符号转换和类型检查,最终调用runtime.mallocgc来为切片分配内存。runtime.mallocgc内部包含一些有趣的逻辑:
// 分配指定大小的对象。
func mallocgc(size uintptr, typ *_type, needzero bool) unsafe.Pointer {
// 一些错误检查和调试代码被省略...
// assistG是用于此分配的G(goroutine),如果GC未激活则为nil。
var assistG *g
if gcBlackenEnabled != 0 {
assistG = getg()
// 对当前的goroutine进行“收费”。
assistG.gcAssistBytes -= int64(size)
if assistG.gcAssistBytes < 0 {
// 当goroutine有分配债务时,调用gcAssistAlloc进行GC工作。
gcAssistAlloc(assistG)
}
}
// 实际分配代码被省略...
}
在上面的代码中,if assistG.gcAssistBytes < 0这行检查我们的goroutine是否有分配债务。分配债务是一种奇特的说法,意思是这个goroutine在GC周期期间分配的内存比它做GC工作的多。
你可以把这想象成你的goroutine在GC周期期间分配时必须支付的税,除了这个税必须提前支付,然后才能实际进行分配。此外,税是与goroutine试图分配的数量成比例的。这提供了一定程度的公平性,使得分配很多的goroutines为这些分配付出代价。
因此,假设这是我们的goroutine在当前GC周期中第一次分配,它将被强制做GC assist工作。这里有趣的一行是对gcAssistAlloc的调用。
这个函数负责一些清理工作,最终调用gcAssistAlloc1来执行实际的GC assist工作。我不会深入gcAssistAlloc函数的细节,但本质上它做以下事情:
- 检查goroutine是否在做一些不可抢占的事情(即系统goroutine)
- 执行GC标记工作
- 检查goroutine是否仍有分配债务,否则返回
现在应该清楚,任何运行并涉及分配的goroutine都将在GC周期期间承担GC Assist的惩罚。由于工作必须在分配之前完成,这将表现为goroutine原本打算做的实际有用工作的延迟或迟缓。
API延迟的影响
在我们的API前端中,这种机制意味着,当GC周期活跃时,goroutine的分配操作会因为辅助GC工作而导致响应延迟。随着服务器负载增加,内存分配的频率上升,这又会触发更多的GC周期(通常每秒高达10到20次)。更多的GC周期意味着更多的GC assist工作,从而使API响应时间增加。
通过执行跟踪,我们可以清楚地看到这一现象。下面是两个跟踪片段:一个在GC周期期间,另一个在非GC周期期间。

跟踪显示了哪些goroutines在哪个处理器上运行。所有标记为app-code的都是执行我们应用程序有用代码的goroutine(例如服务API请求的逻辑)。注意,除了四个专门执行GC代码的处理器外,我们的其他goroutines如何被延迟并被迫做MARK ASSIST(即runtime.gcAssistAlloc)工作。
将此与同一运行应用程序不在GC周期期间的这个配置文件进行比较。这里我们的goroutines大部分时间都在运行我们的应用程序代码,正如预期的那样:

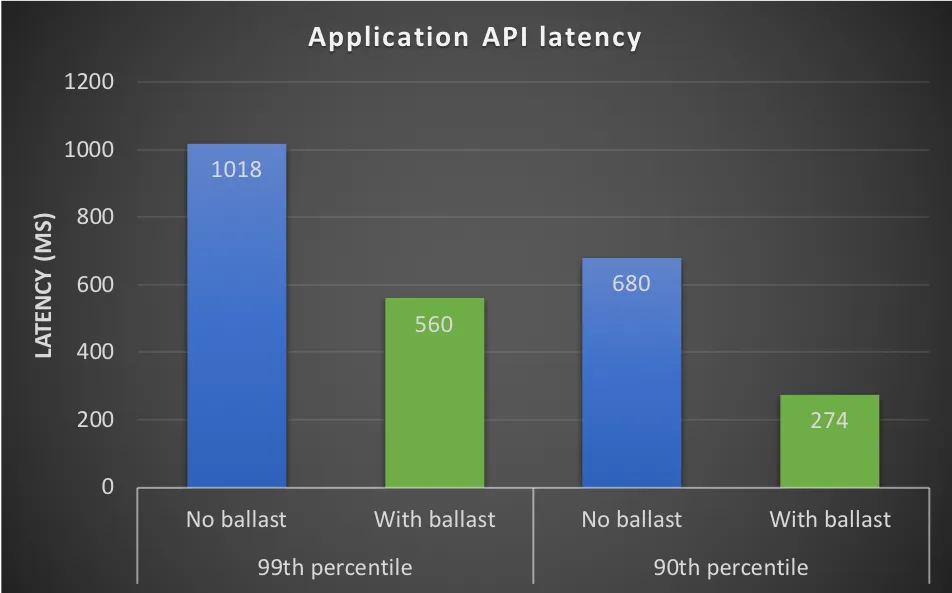
通过减少GC频率,我们显著减少了MARK ASSIST的次数,几乎降低了99%。这直接改善了API的响应时间,特别是在高流量下,使得99百分位的延迟下降了约45%。
为什么选择这种设计?
你可能会好奇,为什么Go选择了这样一种通过GC assist来分摊内存分配负担的设计。实际上,这是为了在并发GC中有效管理堆的增长。在停止世界(STW)的GC中,控制堆增长相对简单,但在并发GC中,我们需要一种机制确保在GC周期期间发生的分配不会导致堆无限制增长。让goroutine为其分配的内存“缴税”,使得这种设计变得相当优雅,也更具公平性。
总结
- 我们发现应用程序在GC操作上花费了大量时间。
- 为此,我们引入了内存镇流器。
- 通过允许堆增长得更大,内存镇流器减少了GC周期的频率。
- 这直接减少了Go GC中的assist延迟,从而改善了API的响应时间。
- 由于镇流器仅消耗虚拟内存,因而其分配成本几乎可以忽略不计。
- 与调整
GOGC参数相比,使用镇流器更容易推理和管理。 - 建议从较小的镇流器开始,并在测试过程中逐步调整。
一些最后的思考
Go在运行时细节上做了很好的抽象,这对大多数程序和开发者来说都是理想的。
然而,当你的应用接近性能瓶颈,不论是在计算、内存还是I/O方面时,深入研究其内部机制就变得至关重要。
在这些情况下,拥有一套强大的工具,如Go提供的调试与性能分析工具,能够帮助快速识别和解决瓶颈,这显然是非常有用的。