ThrottleX——高性能分布式限流库
- Published on
目录
项目简介
ThrottleX 是一个用 Go 语言实现的高性能分布式限流库,提供了三种主流限流算法的实现。该项目特别注重性能优化和分布式场景支持,可以轻松应对高并发环境下的限流需求。ThrottleX 不是一个完整的 Web 服务器;它是一个限速库,旨在与您的 Web 服务器一起工作。ThrottleX 根据定义的策略(如固定窗口、滑动窗口和令牌桶)限制可以到达后端(无论是 Web 服务器、API 等)的请求数量,从而管理请求流。
项目链接
链接:https://github.com/neelp03/ThrottleX
系统架构图
总架构
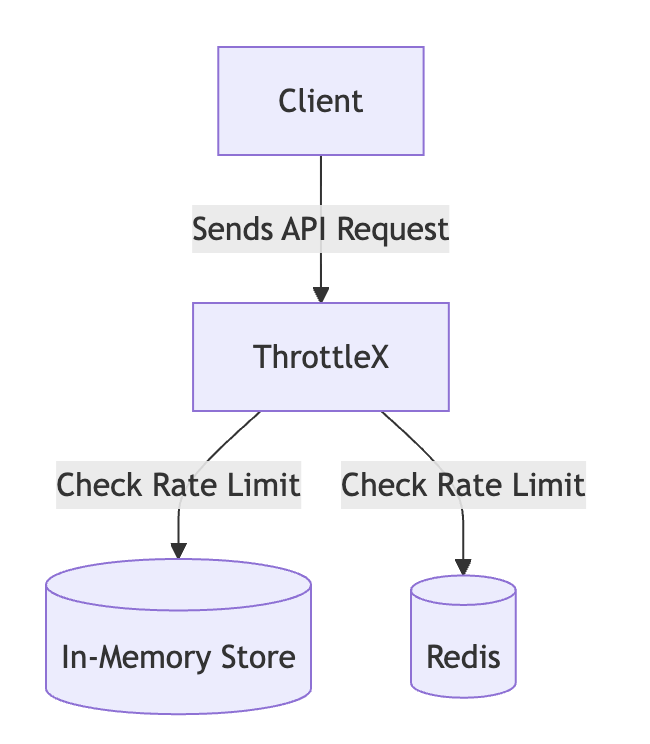
该图显示了客户端请求通过 ThrottleX 系统的流程。根据配置,请求的速率受内存存储或 Redis 限制。
请求流
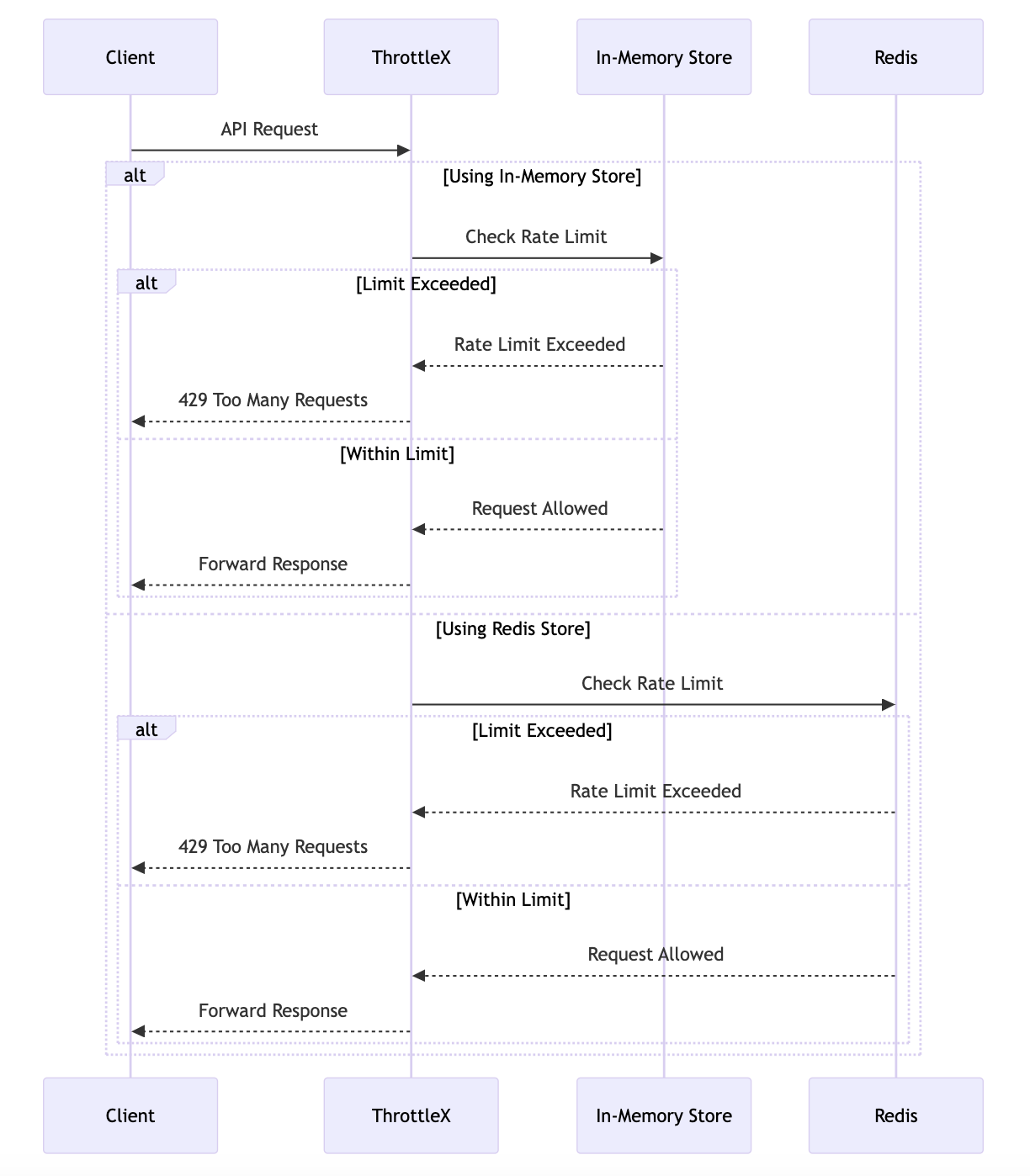
此流程图详细说明了每个请求的交互。根据配置的存储后端,ThrottleX 使用内存存储或 Redis 检查请求是否超出速率限制。如果允许请求,则将响应发送回客户端。
数据存储和限流规则
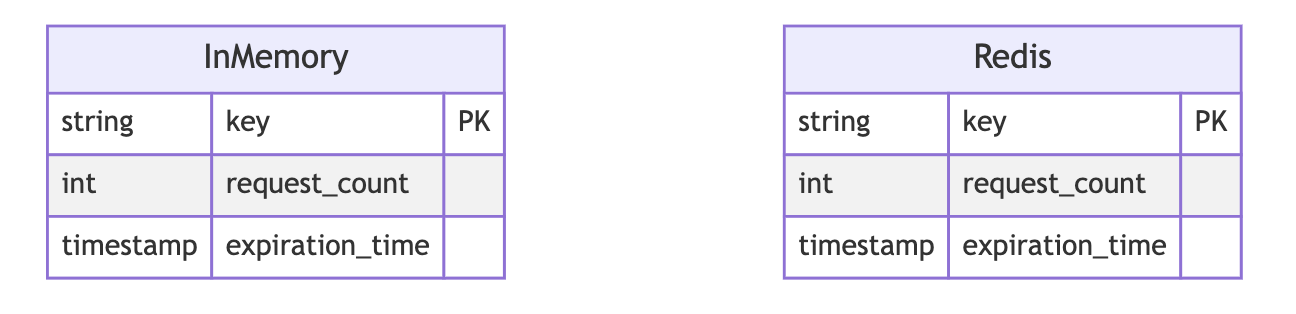
- In-Memory Store:在应用程序内存中存储速率限制数据,例如每个 API 密钥的当前请求数和到期时间。适用于单实例设置。
- Redis:以分布式方式存储速率限制数据,允许 ThrottleX 的多个实例共享速率限制状态。适用于分布式系统。
核心功能
1. 多种限流算法
1.1 固定窗口限流
描述:固定窗口速率限制允许在特定时间窗口内进行固定数量的请求(例如,每分钟 10 个请求)。一旦达到限制,任何其他请求都将被阻止,直到窗口重置。
固定窗口算法的实现如下:
// FixedWindowLimiter 实现了固定窗口限流算法。
// 它限制在固定时间窗口内允许的请求数量。
// 一旦达到限制,所有后续请求都将被拒绝直到窗口重置。
type FixedWindowLimiter struct {
store store.Store // 存储后端,用于跟踪请求计数
limit int // 窗口内允许的最大请求数
window time.Duration // 固定时间窗口的持续时间
}
// Allow 检查给定key关联的请求是否在限流范围内允许通过。
// 它增加当前窗口的计数并判断请求是否应该被允许。
func (l *FixedWindowLimiter) Allow(key string) (bool, error) {
windowKey := l.getWindowKey(key)
count, err := l.store.Increment(windowKey, l.window)
if err != nil {
return false, err
}
if count > int64(l.limit) {
return false, nil // Rate limit exceeded
}
return true, nil // Request is allowed
}
// getWindowKey 为当前时间窗口和客户端key生成一个唯一的key。
// 这确保了每个客户端和时间窗口的计数都被单独跟踪。
func (l *FixedWindowLimiter) getWindowKey(key string) string {}
1.2 滑动窗口限流
描述:滑动窗口速率限制通过维护滑动时间窗口来平滑请求突发,从而提供更精细的控制。限制是在滚动周期内计算的,这有助于更均匀地分配负载。
滑动窗口的核心实现:
// SlidingWindowLimiter 实现了滑动窗口限流算法。
type SlidingWindowLimiter struct {
store store.Store
limit int
window time.Duration
mutexes sync.Map
cleanupTicker *time.Ticker
cleanupStopCh chan struct{}
cleanupInterval time.Duration
}
// NewSlidingWindowLimiter 创建一个新的SlidingWindowLimiter实例。
// getMutex 返回与key关联的互斥锁。
// Allow 检查与给定key关联的请求是否被允许。
func (l *SlidingWindowLimiter) Allow(key string) (bool, error) {
km := l.getMutex(key)
km.mu.Lock()
defer km.mu.Unlock()
km.lastAccess = time.Now()
now := time.Now().UnixNano()
windowStart := now - l.window.Nanoseconds()
// Add the current timestamp to the list of timestamps for this key
err := l.store.AddTimestamp(key, now, l.window)
if err != nil {
return false, err
}
// Count the number of timestamps within the window
count, err := l.store.CountTimestamps(key, windowStart, now)
if err != nil {
return false, err
}
allowed := count <= int64(l.limit)
return allowed, nil
}
// startMutexCleanup 运行一个后台协程来清理未使用的互斥锁。
// StopCleanup 停止互斥锁清理协程。
1.3 令牌桶限流
描述:如果桶中有足够的令牌,令牌桶算法可以处理突发请求。令牌以稳定的速率重新填充,请求会消耗令牌,直到令牌耗尽。
令牌桶算法实现:
// TokenBucketLimiter 实现了令牌桶限流算法。
// 它允许一定量的突发请求,并以稳定的速率补充令牌。
type TokenBucketLimiter struct {
store store.Store // 存储后端,用于跟踪令牌桶状态
capacity float64 // 桶中最大令牌数(突发容量)
refillRate float64 // 每秒向桶中添加的令牌数
mutexes sync.Map // 每个key的互斥锁映射
cleanupTicker *time.Ticker // 定期清理互斥锁的定时器
cleanupStopCh chan struct{} // 用于停止清理协程的通道
cleanupInterval time.Duration // 清理互斥锁的时间间隔
}
// Allow 检查给定key关联的请求是否在限流范围内允许通过。
// 它根据经过的时间补充令牌,并在有可用令牌时消耗一个令牌。
func (l *TokenBucketLimiter) Allow(key string) (bool, error) {
km := l.getMutex(key)
km.mu.Lock()
defer km.mu.Unlock()
km.lastAccess = time.Now()
now := time.Now().UnixNano()
// Retrieve the current token bucket state
state, err := l.store.GetTokenBucket(key)
if err != nil {
return false, err
}
// Refill tokens based on the elapsed time
elapsedTime := float64(now-state.LastUpdateTime) / float64(time.Second)
refillTokens := elapsedTime * l.refillRate
state.Tokens = min(state.Tokens+refillTokens, l.capacity)
state.LastUpdateTime = now
if state.Tokens >= 1 {
// Consume a token
state.Tokens -= 1
err = l.store.SetTokenBucket(key, state, time.Hour*24)
if err != nil {
return false, err
}
return true, nil // Request is allowed
}
// Not enough tokens
err = l.store.SetTokenBucket(key, state, time.Hour*24)
if err != nil {
return false, err
}
return false, nil // Rate limit exceeded
}
// startMutexCleanup 运行一个后台协程来清理未使用的互斥锁。
// StopCleanup 停止互斥锁清理协程。
2. 存储层设计
2.1 统一存储接口
// Store 是限流器使用的存储后端接口。
type Store interface {
// Increment 增加计数器并设置过期时间。
Increment(key string, expiration time.Duration) (int64, error)
// AddTimestamp 向与key关联的列表添加时间戳。
AddTimestamp(key string, timestamp int64, expiration time.Duration) error
// CountTimestamps 计算给定范围[start, end]内的时间戳数量。
CountTimestamps(key string, start int64, end int64) (int64, error)
// GetTokenBucket 获取令牌桶的当前状态。
GetTokenBucket(key string) (*TokenBucketState, error)
// SetTokenBucket 更新令牌桶的状态。
SetTokenBucket(key string, state *TokenBucketState, expiration time.Duration) error
}
// TokenBucketState 表示令牌桶的状态。
// 它包含当前可用的令牌数量和最后更新时间。
type TokenBucketState struct {
Tokens float64 // 桶中当前的令牌数
LastUpdateTime int64 // 最后更新时间的Unix时间戳(纳秒)
}
2.2 内存存储实现
// MemoryStore 是 Store 接口的内存实现
type MemoryStore struct {
mu sync.RWMutex
data map[string]*entry
}
type entry struct {
count int64
expiration time.Time
timestamps []int64 // For sliding window
tokenBucket *TokenBucketState // For token bucket algorithm
}
// startCleanup 运行一个后台 goroutine 来删除过期的条目
// Increment 将给定键的计数器加 1
// AddTimestamp 向与键关联的列表添加时间戳
// CountTimestamps 计算给定范围内的时间戳数量
// GetTokenBucket 获取令牌桶的当前状态
// SetTokenBucket 更新令牌桶的状态
ThrottleX 内置于 Go 中的原因之一是它的 goroutines 和通道,它们以最小的开销为我们提供了疯狂的并发性。以下是 Go 的并发模型对我们产生重大影响的原因:
- Goroutines 很便宜:与传统线程不同,goroutine 占用的内存很小。这意味着我们可以生成数百万个 goroutine,而不会耗尽系统资源。
- 异步处理:通过异步处理请求,我们可以避免阻塞操作。这是在高流量下保持 ThrottleX 响应的关键。每个请求都在自己的 goroutine 中处理,通道促进它们之间的通信以实现顺畅的。
2.3 Redis 存储实现
// RedisStore 是 Store 接口的 Redis 实现
// 它允许速率限制器使用 Redis 存储速率限制数据
// 此实现支持跨多个实例的分布式速率限制
type RedisStore struct {
client *redis.Client // 用于连接 Redis 服务器的客户端
ctx context.Context // Redis 操作的上下文
}
// Increment 在 Redis 中将给定键的计数器加 1
// 如果键不存在,则将其初始化为 1 并设置过期时间
// AddTimestamp 向与键关联的有序集合中添加时间戳
// 同时移除任何超出时间窗口的时间戳
// CountTimestamps 计算给定范围 [start, end] 内的时间戳数量
// 同时移除任何超出时间窗口的时间戳以保持有序集合的整洁
// GetTokenBucket 获取令牌桶的当前状态
// SetTokenBucket 更新令牌桶的状态
分布式速率限制器需要共享状态,这就是 Redis 发挥作用的地方。但我们还需要对其进行优化:
- 密钥过期策略:Redis 为每个速率受限的客户端存储键值对,但为这些密钥设置有效的过期时间至关重要。如果密钥过期速度不够快,就会浪费内存;太快了,您就会忘记速率限制。我们对 TTL(生存时间)进行了微调,以确保我们在内存效率和准确性之间达到最佳平衡点。
- 最小化 Redis 延迟:Redis 已经很快了,但在重负载下,仍然会出现延迟峰值。我们通过调整流水线和复制设置进行了优化。这让我们能够每秒推送更多请求,同时控制数据库延迟。
3. 并发控制
3.1 互斥锁设计
type keyMutex struct {
mu *sync.Mutex
lastAccess time.Time
}
关键优化
内存优化
// startCleanup runs a background goroutine to remove expired entries.
func (m *MemoryStore) startCleanup() {
ticker := time.NewTicker(time.Minute * 5)
for range ticker.C {
m.mu.Lock()
now := time.Now()
for key, e := range m.data {
if now.After(e.expiration) {
delete(m.data, key)
}
}
m.mu.Unlock()
}
}
优化策略:
- 定期清理过期数据
- 高效的数据结构
- 内存复用机制
- 垃圾回收优化
并发是一把双刃剑。虽然 Go 的 goroutines 很轻量,但它们仍然需要内存管理。随着我们的扩展,垃圾收集 (GC) 过程成为瓶颈 - 侵蚀我们的性能,尤其是在重负载下。
我们尽可能地重用 goroutine,减少内存占用并最大限度地减少 GC 开销。我们还为常用的数据结构实现了自定义内存池,以防止不断分配和释放内存。
Redis 优化
// Use a Lua script to ensure atomicity of increment and expiration setting
script := redis.NewScript(`
local count = redis.call('INCR', KEYS[1])
if tonumber(count) == 1 then
redis.call('EXPIRE', KEYS[1], ARGV[1])
end
return count
`)
result, err := script.Run(r.ctx, r.client, []string{key}, int64(expiration.Seconds())).Result()
if err != nil {
return 0, err
}
count, ok := result.(int64)
if !ok {
return 0, fmt.Errorf("unexpected result type: %T", result)
}
return count, nil
}
关键点:
- Lua 脚本保证原子性
- 管道操作减少网络往返
- 连接池管理
- 超时控制
为了确保 Redis 能够跟上巨大的请求负载,我们对管道功能进行了微调。我们不再一次向 Redis 发送每个命令(这会带来延迟),而是将多个命令捆绑在一起,形成一个请求。这使得 Redis 可以并行处理批量命令,从而大大缩短响应时间。
Redis 管道的神奇之处在于它最大限度地减少了网络 I/O 并提高了吞吐量。通过这种优化,Redis 能够以亚毫秒级的延迟每秒处理数百万个请求。
断路器以防止过载
当您处理这种规模的流量时,事情可能会出错,而且肯定会出错。为了防止 ThrottleX 在流量高峰期间不堪重负,我们实施了断路器模式。
工作原理如下:
如果下游服务(如 Redis 或客户端服务)开始滞后或发生故障,断路器将跳闸,立即停止对该服务的请求。 这可以防止过载,使系统能够正常恢复而不会崩溃。
问题解决后,断路器将“重置”,流量将再次正常流动。
这种设计有助于保持高可用性,即使在系统负载过大或出现临时故障的情况下也是如此。如果没有它,当 Redis 复制滞后或流量意外激增时,ThrottleX 就会崩溃。
存在的问题
Go 的垃圾收集
当我们第一次开始扩大规模时,我们注意到在流量大时响应时间会随机出现峰值。深入研究该问题后,我们意识到 Go 的垃圾收集 (GC) 正在无声地导致性能问题。
- 问题:由于有数百万个 goroutine 在飞来飞去,GC 被触发得太频繁,导致影响延迟的暂停。
- 修复:我们通过实现自定义内存池并尽可能重用对象来优化内存分配方式。这降低了 GC 周期的频率,并在流量高峰期间平滑了性能。
- 经验教训:尽管 Go 的内存管理很高效,但在规模上,您需要微观管理内存以避免性能瓶颈。
Redis 复制延迟
虽然 Redis 速度很快,但在每秒处理数百万个请求时,我们遇到了复制延迟。在流量大的情况下,Redis 跨节点复制数据的能力无法跟上写入负载。
- 问题:Redis 复制延迟导致主节点和副本节点之间同步数据的延迟,从而导致分布式系统之间的速率限制不一致。
- 解决方案:我们降低了复制频率,并对 Redis 进行了微调,使其在某些情况下更倾向于高可用性而不是一致性。这让我们获得了更好的性能,但代价是偶尔会出现陈旧数据,但对于速率限制,这种权衡是可以接受的。
- 经验教训:Redis 是一个野兽,但在大规模情况下,为了保持高性能,一致性和可用性之间的权衡是必要的。
网络延迟
在跨分布式节点进行测试时,我们发现网络延迟正在迅速增加,尤其是当请求必须跨区域传输时。在规模上,即使几毫秒的延迟乘以数百万个请求也会导致严重的性能下降。
- 问题:分布式速率限制涉及节点之间和 Redis 之间的持续通信,即使是微小的网络延迟也会累积起来。
- 解决方案:我们通过本地化尽可能多的速率限制逻辑来优化系统,从而最大限度地减少对 Redis 的访问次数。通过首先在本地处理请求并仅定期同步状态,我们减少了对网络调用的整体依赖。
- 经验教训:最小化网络调用对于分布式系统至关重要。您对外部通信的依赖越少,您的系统就会越有弹性和越快。
自适应速率限制
虽然自适应速率限制改变了游戏规则,但在允许流量激增和保持保护之间取得平衡比预期的要困难。
- 问题:起初,速率限制调整得太激进,在高峰期间允许过多的流量,导致暂时过载。
- 解决方案:我们调整了算法,将长期流量趋势考虑在内,随着时间的推移平滑速率调整。这可以防止流量大幅波动,并在持续流量激增期间为系统提供更多喘息空间。
- 经验教训:适应性很强大,但需要进行微调以避免过度纠正。调整过多和调整过少一样危险。