AutoMQ 如何几乎消除了 100% 的 Kafka 跨可用区数据传输成本
- Published on
引言
如果你对消息系统或流处理系统感兴趣,你一定听说过 Kafka。很可能你也遇到过无数声称比 Kafka 更好的解决方案。
这证明了两件事:首先,由于 Kafka 的多功能性,越来越多的公司将其纳入基础设施(这是一个不断增长的市场)。其次,许多用户在运营 Kafka 时遇到困难,尤其是在这个云计算时代(这些都是需要解决的痛点)。
当将 Apache Kafka 迁移到云端时,其复制因子会导致 leader 将接收到的数据发送到不同可用区(AZ)的其他 follower。与计算和存储成本相比,数据传输成本一开始可能并不明显。然而,根据 Confluent 的观察,跨可用区传输成本竟然可能占总账单的 50% 以上(稍后会详细介绍)。
我们发现 WarpStream 通过修改服务发现机制来避免跨可用区传输成本,确保客户端始终与同一可用区的 broker 通信。WarpStream 对 Kafka 协议的重写在这里起到了关键作用。
这篇文章我们将探讨 AutoMQ(一个 100% 兼容 Kafka 的替代解决方案)如何帮助用户显著降低跨可用区传输成本。该解决方案旨在通过利用 Kafka 的代码库处理协议,并重写存储层,引入 WAL 来有效地将数据卸载到对象存储,从而在云端高效运行 Kafka。
跨可用区成本
Apache Kafka 最初是在 LinkedIn 开发的,用于满足公司密集的日志处理需求。它是专门为 LinkedIn 的环境构建的,工程师通过利用页面缓存和磁盘上的顺序访问模式来优化 Kafka。这种方法使他们能够实现非常高的吞吐量,同时保持系统相对简单,因为操作系统处理了大部分存储相关的任务。
Kafka 依靠复制来确保数据持久性。当消息写入 leader 分区时,必须复制到 follower 分区。最初在 LinkedIn 开发时,Kafka 主要在自托管数据中心运行,基础设施团队在 leader 跨不同数据中心复制消息到 follower 时并不考虑网络成本。
然而,当用户将 Kafka 迁移到云端时,情况发生了变化。Leader 将数据复制到不同可用区的 follower 以确保在可用区故障时的数据可用性,但云提供商对跨区数据传输收取网络费用。根据 Confluent 的观察,在自管理 Apache Kafka 时,由于复制导致的跨可用区数据传输成本竟然可能占基础设施成本的 50% 以上。
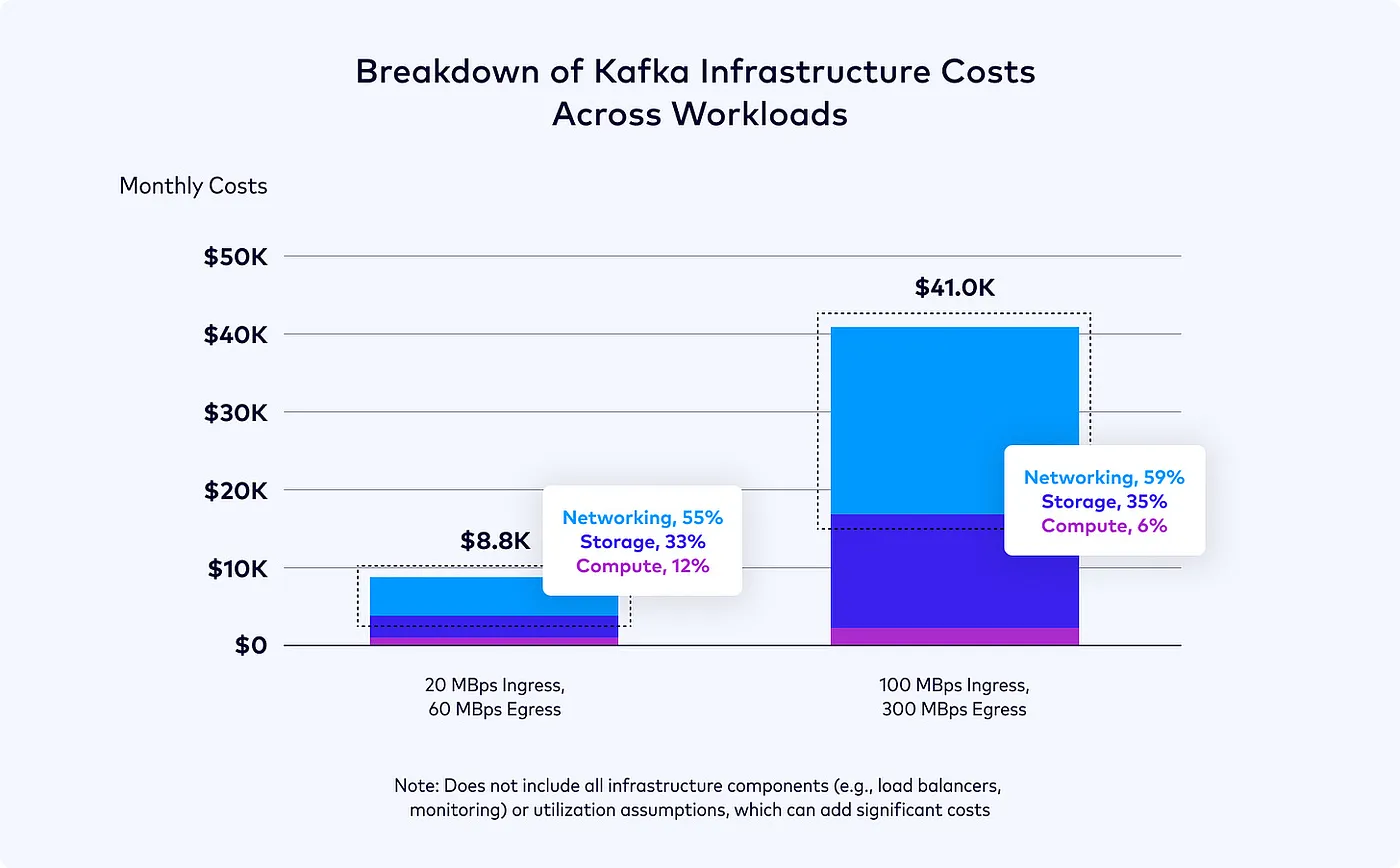 Confluent 关于掌握 Kafka 基础设施成本的指南 (2023)
Confluent 关于掌握 Kafka 基础设施成本的指南 (2023)让我们来看一些具体数字:假设有一个跨三个可用区部署的三节点 Kafka 集群。如果其中一个可用区的 broker 宕机,集群仍然可以通过剩余的两个 follower 继续服务。在一个均衡的集群中,分区 leader 会尽量分布在三个可用区中,这意味着大约三分之二的时间,生产者会向其他可用区的 leader 写入数据。
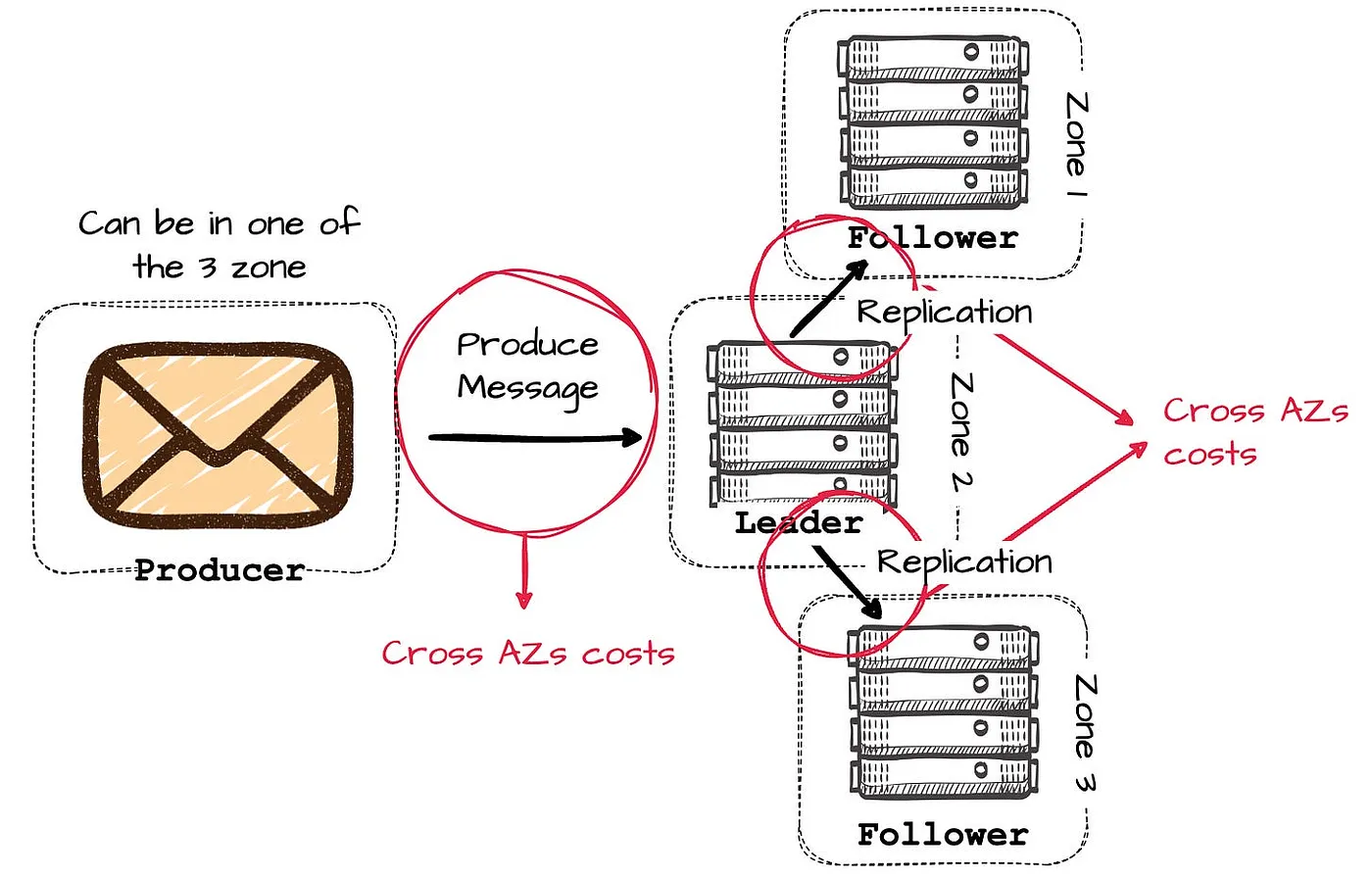
一旦 leader 接收到消息,它会将数据复制到其他可用区的 broker 以确保高数据可靠性,这导致产生了初始生产请求两倍的跨可用区流量。
简而言之,Apache Kafka 的多可用区部署架构至少会产生 (2/3 + 2) 倍于单位价格的跨可用区流量(在 AWS 中为 $0.01/GB,入站和出站流量分开计费)。
以上计算还未考虑消费者的跨可用区成本。
如果我们使用三台 r6i.large(2 核心-16GB 内存)的 broker,提供 30MiB/s 的写入吞吐量,Apache Kafka 的月度跨可用区流量成本计算如下:
30 * 60 * 60 * 24 * 30 / 1024 * (2 / 3 + 2) * 0.02 = $4050
而虚拟机成本仅为:3 * 0.126 $/h(r6i.large 单价)* 24 * 30 = $272(仅占跨可用区流量成本的 6.7%)
AutoMQ 概述
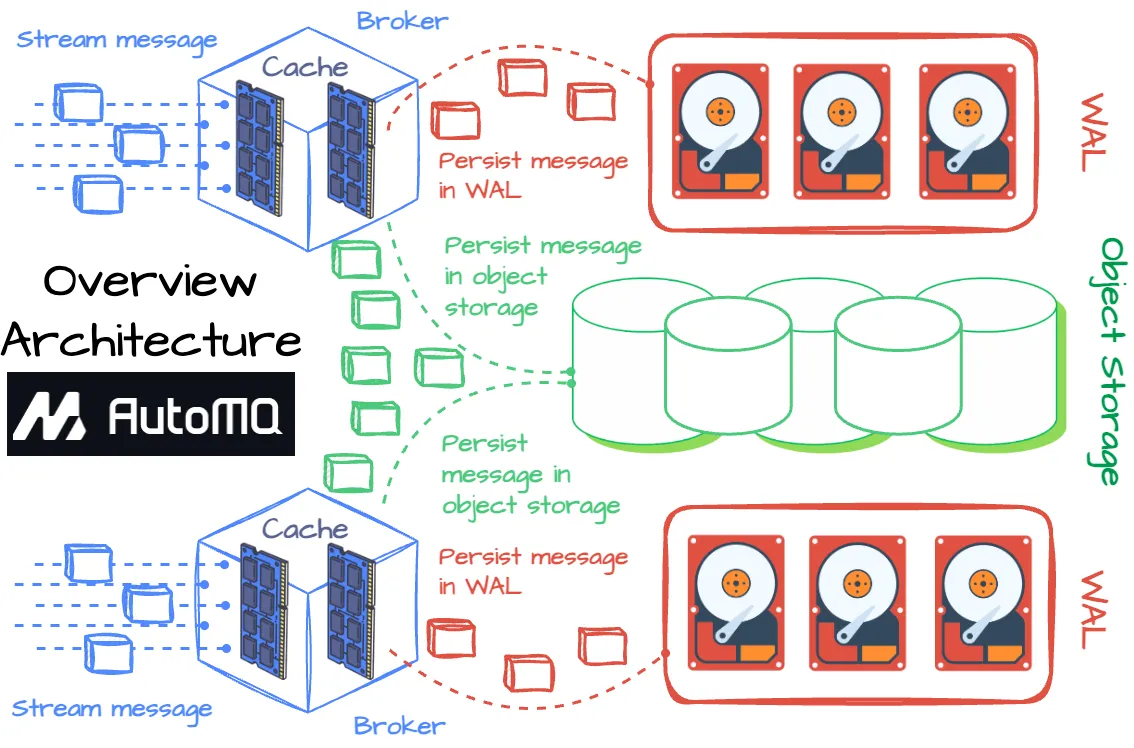 AutoMQ 架构概览
AutoMQ 架构概览AutoMQ 旨在通过将所有消息写入对象存储来提高 Kafka 的效率和弹性,同时不影响性能。
为实现这一目标,AutoMQ 重用了 Apache Kafka 的计算和协议码,并引入共享存储架构来替代 Kafka broker 的本地磁盘。从高层次来看,AutoMQ broker 将消息写入内存缓存。在异步将消息传输到对象存储之前,broker 必须将数据写入预写日志(WAL)存储以确保持久性。
预写日志是一种用于崩溃恢复和事务恢复的追加式磁盘结构。数据库的变更在写入数据库之前,会首先记录在这个结构中。
AutoMQ 使用堆外缓存内存层来处理所有消息的读写,提供实时性能。EBS 设备作为 AutoMQ 的 WAL;当 broker 接收到消息时,它会将消息写入内存缓存,并且只有在消息持久化到 WAL 后才返回确认。EBS 同时也用于 broker 故障时的数据恢复。
所有 AutoMQ 数据都存储在对象存储中,使用 AWS S3 或 Google GCS。broker 从日志缓存异步写入数据到对象存储。对于元数据管理,AutoMQ 利用了 Kafka 的草稿模式。
AutoMQ 的 WAL 的一个重要特性是其灵活性,允许用户根据具体用例选择不同的存储选项。例如,如果 AWS 在未来发布更先进的磁盘设备,用户可以无缝采用这个新的存储选项来提升 AutoMQ 的性能。
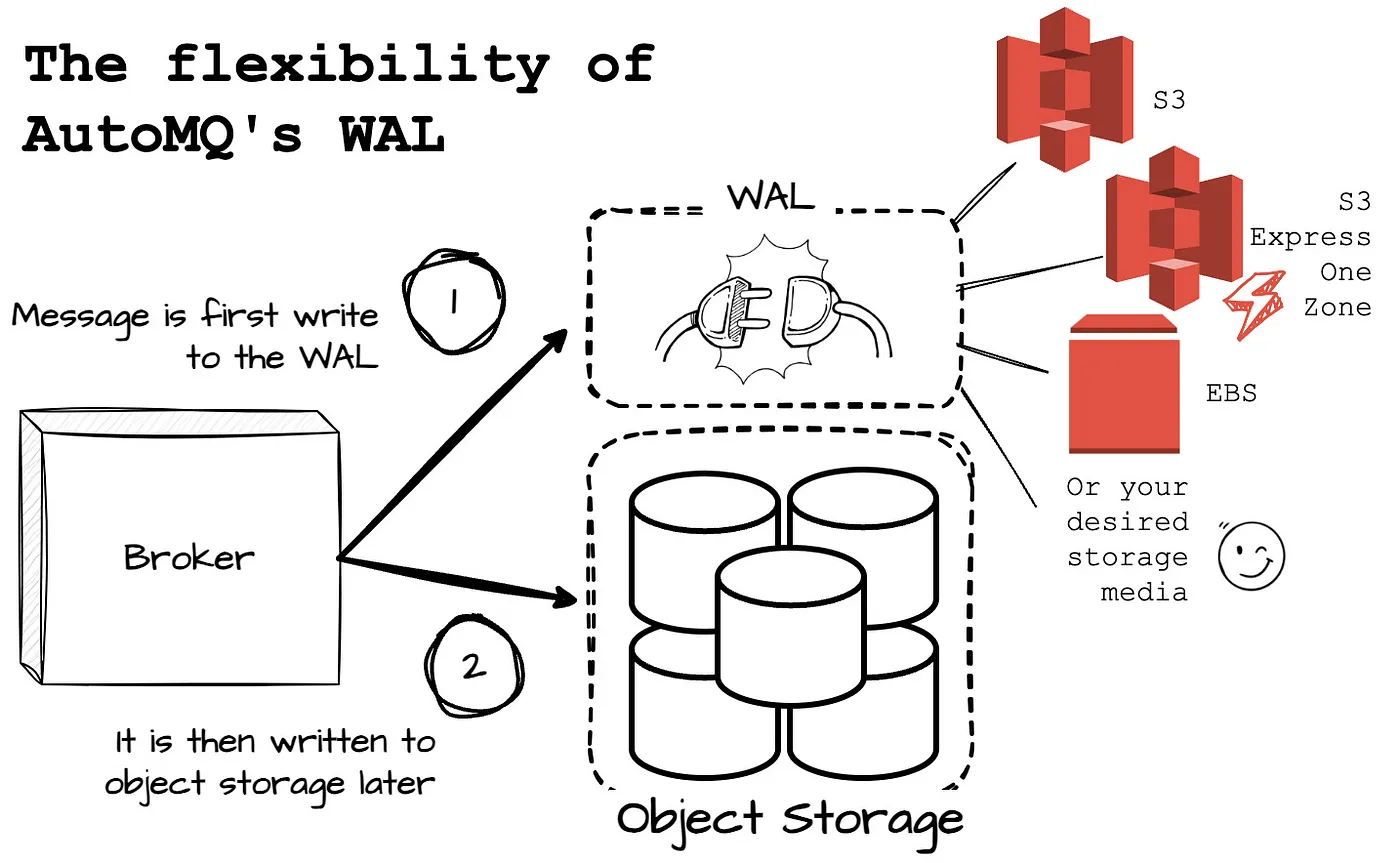 AutoMQ WAL 存储选项示意图
AutoMQ WAL 存储选项示意图AutoMQ 如何降低跨可用区成本
生产路径
使用 EBS WAL 时,虽然无法完全消除跨可用区数据传输成本,但由于数据存储在 S3 中且不需要在 broker 之间复制,AutoMQ 显著降低了这些网络成本。然而,当生产者向不同可用区的 leader 分区发送消息时,客户仍需支付跨可用区数据传输费用。
AutoMQ 引入了一个使用 S3 作为 WAL 的解决方案来消除跨可用区数据传输成本。与将数据先写入 EBS 再写入 S3 不同,S3 WAL 允许 broker 直接将数据写入 S3,确保生产者只向同一可用区内的 broker 发送消息。
在 Kafka 中,生产者在发送消息之前,会向引导服务器发送元数据请求以获取分区 leader broker 的身份信息。在生产数据时,客户端总是尝试与指定主题分区的 leader 通信。
在 Kafka 中,写入操作始终通过 leader 完成。
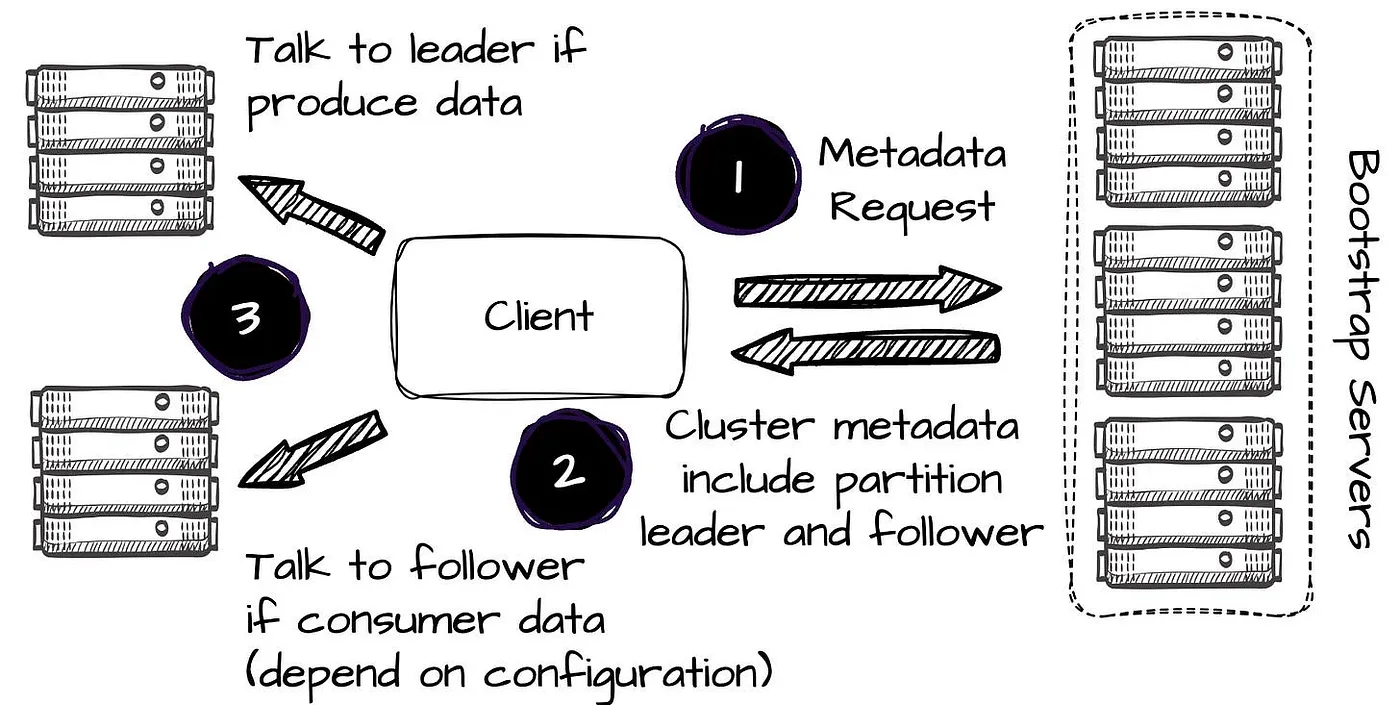 Kafka 中的写入流程
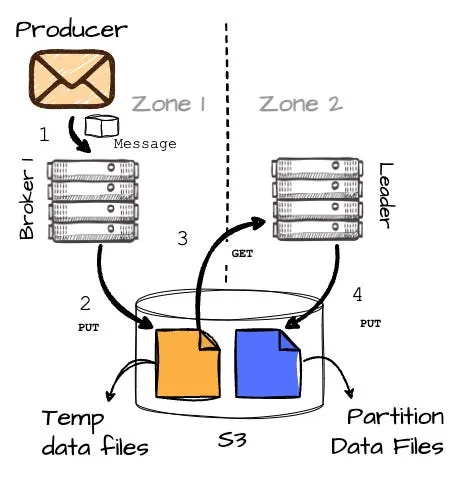
Kafka 中的写入流程而在使用 S3 WAL 的 AutoMQ 中,情况有所不同。想象一个场景:生产者在 AZ1而分区 P2 的 leader(B2)在 AZ2,同时在 AZ1 中还有一个 broker 1(B1)。让我们来看看这种方法下消息生产的完整路径。
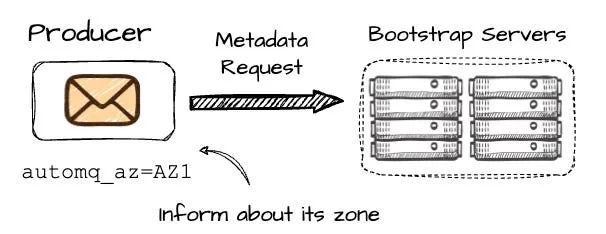
- 当生产者想要写入 P2 时,它首先向引导 broker 集合发送元数据请求;生产者必须包含其所在可用区(本例中为 AZ1)的信息。
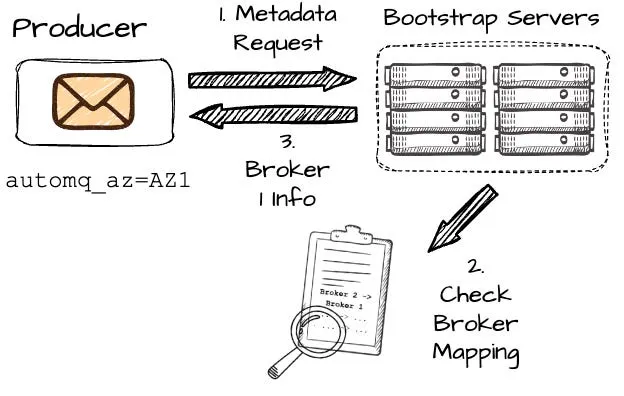
 元数据请求流程示意图
元数据请求流程示意图在 Kafka 中,发送元数据请求后,生产者可能会收到与其位于不同可用区的 broker B2 的信息,这会导致跨可用区成本。然而,AutoMQ 的目标是避免这种情况。
- 在 AutoMQ 端,使用一致性哈希算法将 broker 映射到不同的可用区。例如,假设 AutoMQ 将 AZ2 中的 B2 映射到 AZ1 中的 B1。由于 AutoMQ 知道生产者 Pr1 在 AZ1(基于元数据请求),它会为此请求返回 B1 的信息。如果生产者与 B2 在同一个可用区,则会返回 B2 的信息。核心思想是确保生产者始终与同一可用区的 broker 通信,有效避免跨可用区通信。
- 在收到 B1 的信息后(请注意,这个 broker 并不负责目标分区),生产者开始向 B1 发送消息。
- B1 在内存中缓冲消息,当达到 8MB 或经过 250ms 后,将缓冲的数据作为临时文件写入对象存储。
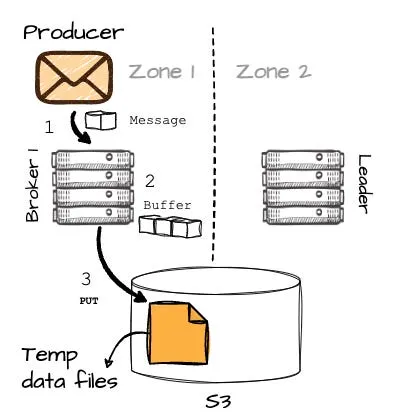 AutoMQ 消息写入完整流程图
AutoMQ 消息写入完整流程图- 这里有一个有趣的地方:在成功将消息写入 S3 后,B1 会向 B2(分区的实际 leader)发送 RPC 请求,通知它临时数据的位置(这会在不同可用区的 broker 之间产生少量的跨可用区流量)。
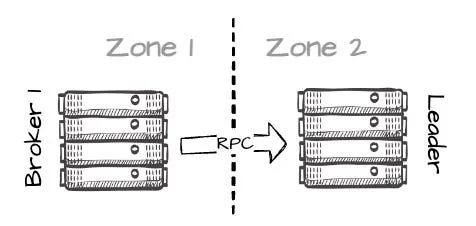
- B2 随后会读取这些临时数据并将其追加到目标分区(P2)。一旦 B2 完成数据写入分区,它会响应 B1,然后 B1 最终向生产者发送确认。
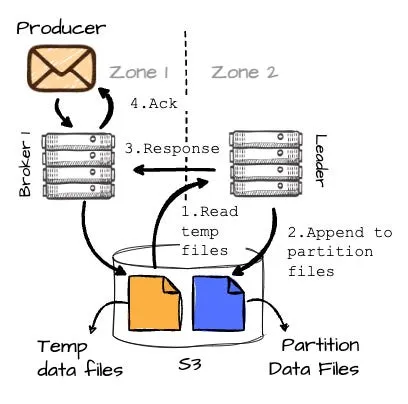
这里有一张图表帮助你理解整个过程:
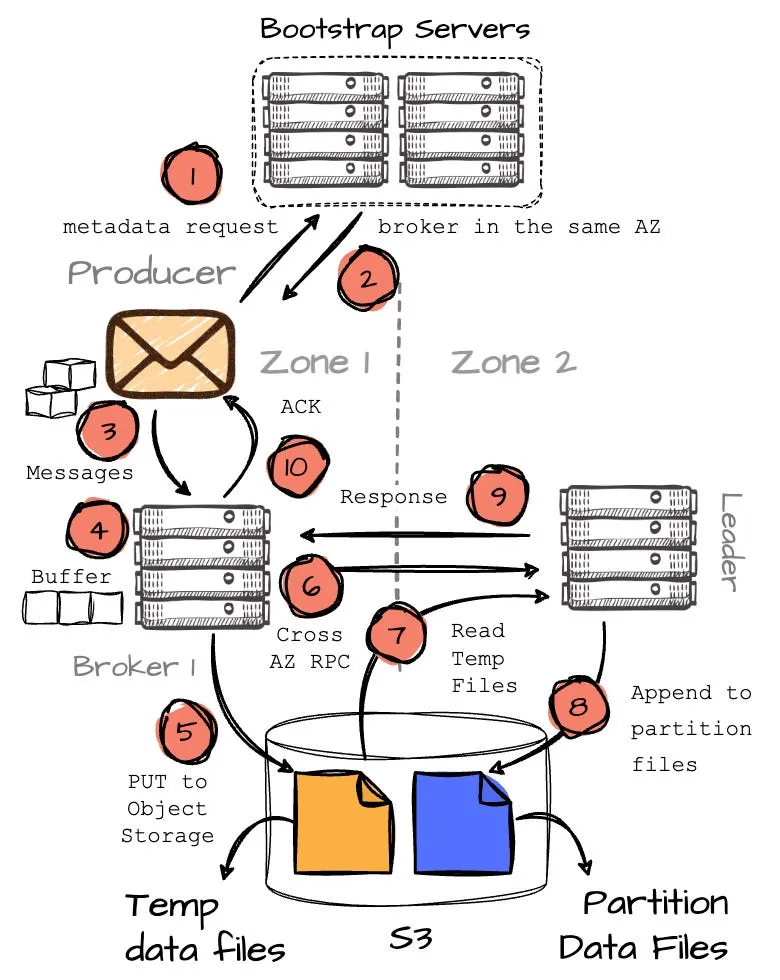
这种方法完全消除了跨可用区数据传输成本,但客户需要比使用 EBS WAL 时部署更多的虚拟机实例(代理)。这是因为云环境中虚拟机和网络吞吐量的限制。与 EBS WAL 相比,需要从 S3 读取额外的数据,这会消耗虚拟机的网络带宽。换句话说,S3 WAL 需要更多的虚拟机来处理增加的网络吞吐量,以确保维持与 EBS WAL 相同的读写性能。
消费路径
对于消费路径,过程几乎与 Kafka 相同。得益于 100% 的 Kafka 兼容性,AutoMQ 消费者可以利用 Kafka 的机架感知特性来实现数据消费路径,确保从同一可用区的 broker 拉取数据。
关于 AutoMQ 如何帮助消费者消除跨可用区成本的另一个重要因素是其内部自平衡机制。该机制包括内置的机架感知分区调度,确保 AutoMQ 在多个可用区的 broker 之间平衡分区。
虽然 Apache Kafka 支持机架感知机制,但仅凭这个特性无法完全消除跨可用区流量。要防止跨可用区流量成本,Apache Kafka 需要在整个运行过程中保持跨可用区的分区平衡,即使在扩缩容、分区迁移或其他过程中也是如此。AutoMQ 通过其自平衡机制为用户自动管理这些操作。这不仅确保了流量平衡和系统在故障时的自我修复,还在降低跨可用区流量成本方面发挥着关键作用。
观察结果
用户可以根据不同场景选择最优的 WAL 实现方案。对于对延迟敏感的场景,如反欺诈、金融交易或实时数据分析,建议使用 EBS WAL。对于那些延迟不是首要考虑因素的用例,如日志收集或可观测性数据摄入,使用 S3 WAL 可以带来显著的成本节省。
从上面的分析中我们了解到,WAL 的实现在 AutoMQ 中扮演着关键角色。WAL 被设计成可插拔的,这意味着如果出现更先进的云存储选项,比如最近推出的 S3 Express One Zone,用户可以轻松地将其集成到 WAL 中。这种方法使 AutoMQ 能够充分利用新兴云存储解决方案的优势来适应各种用户场景。通过抽象化 WAL,AutoMQ 可以快速利用不同云存储介质的优势,体现了 AutoMQ 所说的"One for All"理念。
总结
在本文中,我们了解到当用户在云端运行 Apache Kafka 时,跨可用区成本可能占据云账单的很大一部分。这些成本主要来自两个因素:生产者向不同可用区的 leader 发送流量,以及在 broker 之间复制数据的需求。
接着,我们探讨了 AutoMQ 如何通过让生产者向同一可用区的 broker 发送消息来应对这一挑战。数据以批量方式写入 S3,之后由 leader 分区获取该数据并将其追加到正确的分区中。通过这种方式,AutoMQ 帮助减少了几乎 100% 的跨可用区成本。(当 broker 跨区发出 RPC 请求时仍会产生少量的跨可用区流量。)