GPU网络通信基础
- Published on
目录
背景动机
训练大型语言模型(LLM)需要大量的浮点运算(FLOPs):

训练这些模型需要多长时间?
如果单个GPU每秒能执行约2 PetaFLOP(2 * 10^15浮点运算),一天有86,400秒,那么大约能达到1.7 x 10^20 FLOPS。在最理想的情况下,使用单个GPU,要达到10^24 FLOPs,你将需要约16年的训练时间。
16年!没人有这么多时间!
我们如何才能在数月甚至数周内训练出LLM?我们需要大量GPU同时工作。
这些GPU还需要相互通信,共享它们协同工作时的进度和结果。这种通信如何实现?网络通信!

不,不是这种社交网络。

是的,就是这种计算机网络!😅
连接GPU实际上是一个相当有趣的问题。想象一下xAI需要协调20万个GPU之间的通信!
网络交换机
以xAI的20万GPU集群为例,如何连接它们?
在理想情况下,每个GPU都能以最快的速度与其他所有GPU通信。
首先想到的方案是:直接连接每个GPU和其他所有GPU。
不需要通过交换机或其他设备中转,因此通信应该非常快!
这被称为"全网状网络"(full mesh network)。
但在大规模场景下,全网状网络存在很多实际问题。
例如,要直接连接GPU对,每个GPU需要199,999个端口,我们总共需要约200亿条线缆!这显然不可行。
如果我们引入网络交换机呢?网络交换机是一种专用硬件,可以高效地在多个设备(在这种情况下是GPU)之间路由数据。
与其让每个GPU直接连接到其他所有GPU,我们可以将GPU连接到交换机,由交换机管理它们之间的通信。
 网络交换机连接这些GPU,使它们能够相互通信
网络交换机连接这些GPU,使它们能够相互通信
对于20万个GPU的集群,使用单个网络交换机将每个GPU的连线简化为一条,从200亿条线缆减少到仅20万条!
但这样的交换机仍需要20万个端口,这在实际上也不可行。
 这种交换机需要放大8000倍才够用 😂
这种交换机需要放大8000倍才够用 😂
显然,一个巨型交换机无法解决问题,因此我们需要分层交换架构。
叶脊拓扑结构
与其使用一个巨大的交换机连接所有GPU,我们可以将网络组织成交换机的层次结构:

这种层次结构中的每个交换机可以更小,只连接一部分GPU,使其在尺寸和成本上更加可管理。
通过这种解决方案,GPU不再需要成千上万的直接连接,交换机也是如此!
然而,代价是当不同分支上的GPU需要通信时,数据必须通过多个交换机,引入额外的延迟。
举例说明,考虑两个没有连接到同一交换机的GPU。它们之间不再有直接连接,通信必须先到达高级交换机,再下行到目标GPU的交换机。
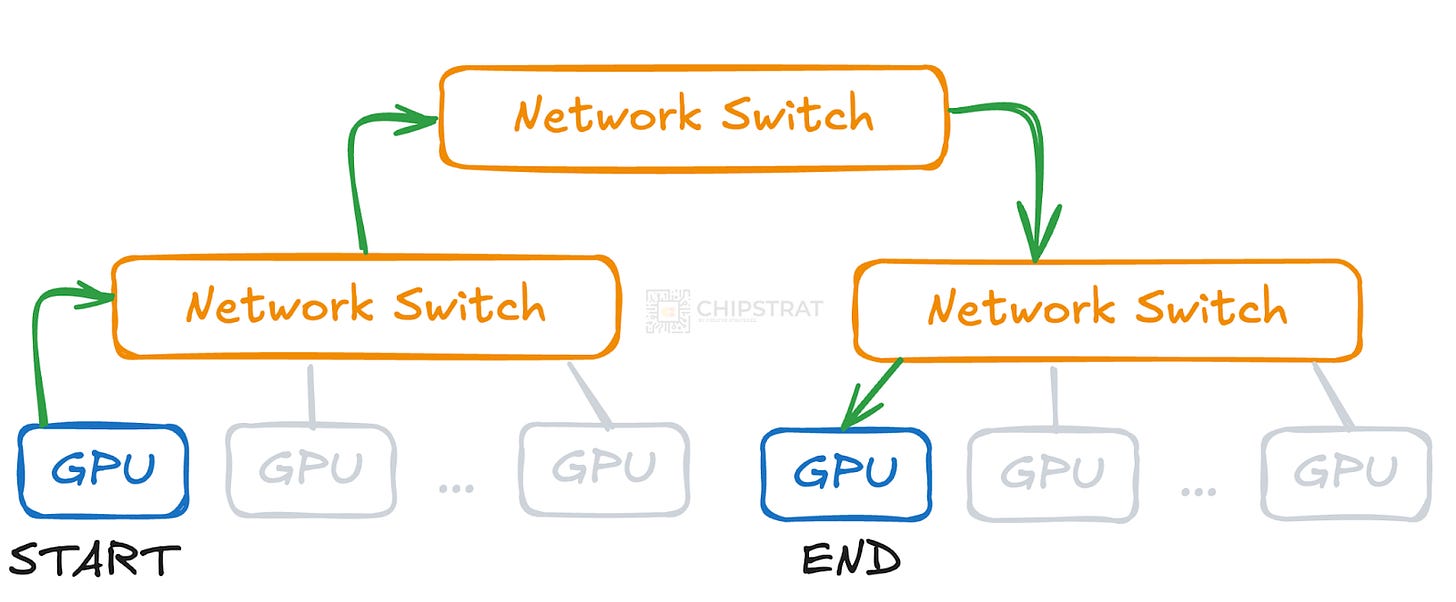 网络跳转增加了数据传输的时间
网络跳转增加了数据传输的时间
这种两层架构通常被称为叶脊架构或两层Clos网络。
叶交换机直接连接计算节点,脊交换机连接叶交换机:

横向扩展(Scale Out)
如何实现数千GPU的规模?
横向扩展或水平扩展是通过添加更多GPU和网络交换机来扩展集群的方法。这有助于跨更多硬件分配训练工作负载,从而减少训练LLM所需的时间。
 只需复制并粘贴网络架构...实现横向扩展!
只需复制并粘贴网络架构...实现横向扩展!
这些GPU和交换机如何通信?横向扩展使用以太网或InfiniBand,这两种技术都能提供GPU间通信所需的高速网络连接。
InfiniBand是英伟达的专有技术(通过收购Mellanox获得),由于其相比高性能以太网变体(如RoCE,即融合以太网上的RDMA)具有更低的延迟和更高的带宽,在大规模AI集群中历来更受青睐。
 如果你说这不是以太网线缆,你是对的!这是适用于Quantum-2交换机的1.5米(5英尺) NVIDIA/Mellanox MCP4Y10-N01A兼容800G OSFP顶部散热InfiniBand NDR无源直连铜缆
如果你说这不是以太网线缆,你是对的!这是适用于Quantum-2交换机的1.5米(5英尺) NVIDIA/Mellanox MCP4Y10-N01A兼容800G OSFP顶部散热InfiniBand NDR无源直连铜缆
以太网在新的训练集群中越来越受欢迎。正如Jensen在本周英伟达GTC主题演讲中分享的,Elon的xAI使用英伟达的Spectrum X以太网构建了最大的训练集群(Colossus)。
纵向扩展(Scale Up)
横向扩展运行一段时间后,物理和经济因素开始限制其发展。更多设备和交换机意味着额外的跳转延迟、更高的功耗和成本上升。在某个点上,单纯的横向扩展不再是最佳解决方案。
这引出了另一种方法:纵向扩展或垂直扩展。
纵向扩展意味着增加每个节点的计算能力,而不是增加更多节点。
每个叶交换机不直接连接到单个GPU,而是连接到包含多个GPU(比如每台服务器8个)的服务器。这减少了所需的直接网络交换机和线缆数量:
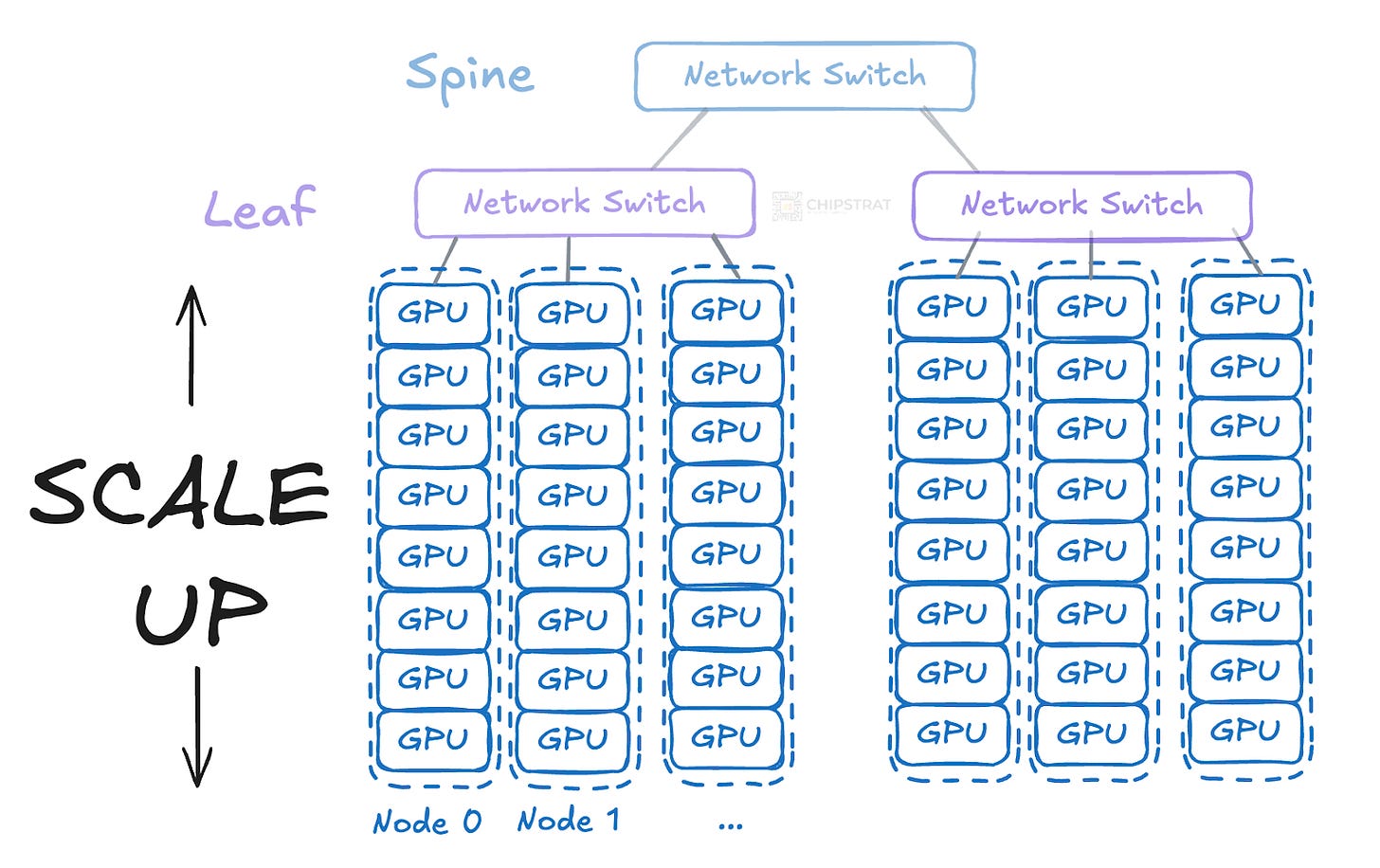 每个服务器节点包含8个GPU;单个交换机可以管理更多GPU
每个服务器节点包含8个GPU;单个交换机可以管理更多GPU
打个比方,在网络扩展的早期阶段,快速增长的公司可能首先通过增加CPU核心和内存来升级服务器。这是垂直扩展。当单个机器不够用时,他们会添加更多服务器和负载均衡器来分配流量。这是水平扩展。
细心的观察者可能会想知道这些纵向扩展的GPU如何相互通信。它们不是仍然需要通过网络交换机连接吗?如果是,这与横向扩展有何不同?
非常好的观察!
节点内通信与节点间通信
服务器节点内的通信称为节点内(intra-node)通信。

不同服务器节点上GPU之间的通信称为节点间(inter-node)通信。

事实证明,相邻节点内的GPU可以比使用节点间InfiniBand或以太网技术更快、更高带宽地通信。
为什么?
这主要是由于GPU的物理接近性和采用的专用互连技术。这些技术使用直接、短距离且优化的信号线路,通常直接集成在同一电路板上或共享封装内。这减少了信号传输距离并最小化了延迟。
例如,这是2018年IEEE国际固态电路会议(ISSCC)论文集中分享的AMD Infinity Fabric路由示意图:
 亮色连接线(traces)代表计算单元之间的金属连接。可以将其视为封装基板中的"线路"。
亮色连接线(traces)代表计算单元之间的金属连接。可以将其视为封装基板中的"线路"。
由于服务器内的GPU直接连接,它们可以避免节点间GPU服务器通信相关的大部分开销。封装内路由通过保持短线距、减少传播延迟和最小化信号衰减来提高效率。
InfiniBand和以太网等外部连接通常需要额外的信号完整性组件——如中继器、重定时器和纠错机制——以保持较长距离的可靠传输。这些可能会引入增量延迟并增加功耗。
我喜欢将节点内通信(如NVLink和InfinityFabric)比作德国高速公路(Autobahn):设计为无中断高速行驶。
节点间通信则像双车道公路:速度较慢,容量有限,而且在春季播种或秋季收获期间可能需要减速绕过拖拉机(即处理拥堵)。
 小心,前面可能有警车!
小心,前面可能有警车!
训练过程中的通信
了解神经网络的训练方式有助于理解通信挑战。
在每个训练周期中,网络首先执行前向传播,输入数据流经网络各层产生预测结果。然后通过损失函数将这一预测与正确答案进行比较,量化预测的偏差程度。
学习的核心发生在反向传播过程中,一种叫做反向传播的算法计算网络中每个权重对误差的贡献程度。利用这些信息,梯度下降算法调整所有权重朝着减少误差的方向——本质上是调整数十亿个"旋钮",逐步提高网络的准确性。通过每次迭代,这些渐进式调整使神经网络能够在新数据上做出更可靠的预测。
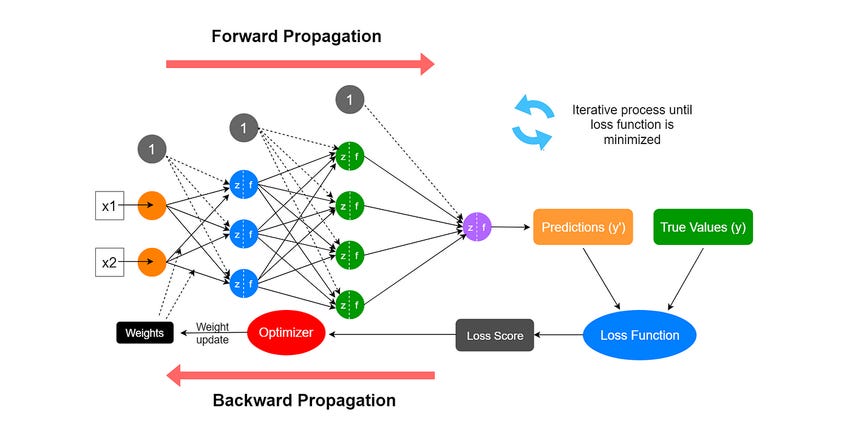 神经网络前向传播过程
神经网络前向传播过程
每个GPU基于前向传播的误差计算权重更新的梯度,但由于每个GPU在不同的数据子集上工作,这些梯度只是部分结果。为确保所有GPU应用相同的更新并保持同步,需要在GPU间聚合和平均梯度。
这个过程,被称为all-reduce通信,允许GPU交换和分发最终计算值,然后更新它们的本地模型。通过维持全局一致性,这防止了模型偏移并确保有效的分布式训练。
all-reduce通信的延迟直接影响训练效率。
英伟达的NCCL软件库还支持其他集体操作,例如:AllReduce、Broadcast、Reduce、AllGather和ReduceScatter。
正如我们在DeepSeek V3中看到的,有软件方法可以重叠通信和计算,减少GPU空闲时间,降低通信约束的影响。
结论
这是第一部分的全部内容。正如承诺的,内容非常温和!
还有很多内容需要讨论。实际的大规模集群并不是全网状的;情况更复杂。
但希望你已经掌握了足够的知识,当看到图表和文档时,例如这张英伟达SuperPOD计算架构图,能够获得高层次的理解并提出问题以填补知识空白:

在上图中,我们可以看到脊交换机和叶交换机如何帮助横向扩展,以及B200服务器如何实现纵向扩展。
从表格中可以看出,每个可扩展单元(SU)有32个节点,每个节点有8个GPU。所以这是横向扩展(32个节点)和纵向扩展(每节点8个GPU)的结合。忽略"移除一个DGX以容纳UFM连接"的细节;重点是你现在可以大致理解这些内容了!